BERT(Bidirectional Encoder Representations from Transformers)是Google的研究團隊2018年時開發的自然語言處理模型。BERT在被提出之後在多項自然語言處理任務中或的最優秀的成績,並且許多語言模型都是以BERT為基礎進行調整和擴展,由此可見BERT在自然語言處理領域的發展有著極其重要的作用。
當BERT問世後就迅速重新定義自然語言處理任務的水準,並且在當時的NLP評估標準中表現優異,已然成為一時之選。然而儘管原版BERT現在已經不再位於榜首,還是能夠看到BERT有著優秀的表現,甚至有時還能夠在排行榜前幾名看到他。現今大多都是根據BERT核心思想所衍生出的模型,或是經過改進和修改以超越的模型。從這段話可以清楚顯示出BERT在自然語言處理領域的影響力和關鍵地位。
這個模型與芝麻街的黃色布偶同名,並不是因為Google命名BERT時直接受到芝麻街中的BERT角色的影響,而是出自工程師的創意。儘管BERT和芝麻街的BERT同名,但並沒有直接的聯繫或特定的原因,它純粹是工程師為這一技術所選擇的名稱,這樣的命名方式使模型變得更加易於理解和記憶。
BERT模型的建立有使用其他模型的訓練上下文相關表示模型的技巧。而不同於這些模型,它們通常是單向的,BERT模型則是採用了更深度雙向架構,因此能夠同時學習文本上下文之間的關係,而不僅僅是依靠單一方向的信息。
BERT模型可分為兩種版本,分別為Base和Large,主要區別在於模型的參數大小。Base的模型包括12層Transformer,每個隱藏層大小為768,並且擁有12個Self-Attention。總共,Base模型的參數量110M個參數。Large模型則更大,包含24層Transformer,每層隱藏層大小為1024,並且有16個Self-Attention,Large模型包含約340M個參數。
Google在預訓練BERT時會讓它進行Masker LM和Next Sentence Prediction的預訓練任務,我們簡單解說一下這兩個任務
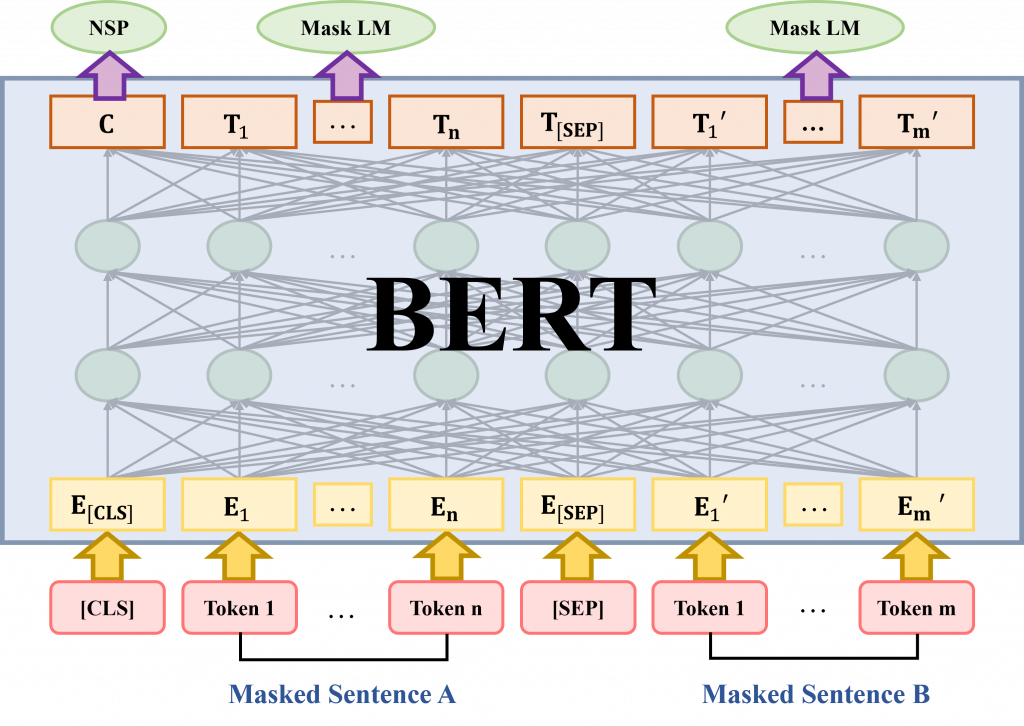
BERT在預訓練過程中使用了包括Books Corpus和英文Wikipedia等大型文本資料集。特別是在Wikipedia資料集中,它僅提取了文本段落作為訓練資料。預訓練BERT模型需要處理這麼龐大的訓練資料,這不僅需要大量的計算資源,還需要相當多的時間。
說完了BERT的相關介紹了,該開始進行實作練習了,我會使用IMDB數據集微調模型,而IMDB是是一個電影相關的線上資料庫,內部資料集共有50000筆影評,訓練資料與測試資料各25000筆,每一筆影評都被分為正評或負評,接下來會利用PyTorch以及huggingface的套件:Transformers和datasets套件,使用transformers套件可以更便利的微調模型,而datasets則是可以有著不少的公開數據集可以使用。所以先安裝transformers和Datasets套件吧
pip install transformers
pip install datasets
import os
import re
import csv
import time
import torch
import numpy as np
import pandas as pd
import transformers
import torch.nn as nn
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
from tqdm import tqdm
from datasets import load_dataset
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score
from tensorflow.keras.preprocessing.sequence import pad_sequences
from torch.utils.data import TensorDataset, DataLoader, RandomSampler
from transformers import BertTokenizer, BertForSequenceClassification, get_linear_schedule_with_warmup
接著要進行超參數的設置,設置batch_size為32,epochs為10次,學習率為1e-4,文本鋸子的長度為128個字
def super_parameter():
setting_batch_size = 32
setting_epochs = 10
setting_lr = 1e-4
setting_max_len = 128
if __name__ == '__main__':
print(f"batch_size: {setting_batch_size}, epochs: {setting_epochs}, learning_rate: {setting_lr}")
return setting_batch_size, setting_epochs, setting_lr, setting_max_len
batch_size, epochs, lr, max_len = super_parameter()
Seed = 42 # 設定亂數種子
torch.manual_seed(Seed)
np.random.seed(Seed)
# 調用GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
train_on_gpu = torch.cuda.is_available()
if train_on_gpu:
device = torch.device(f'cuda:{0}')
print("using the GPU{%s}" % torch.cuda.get_device_name(0))
else:
device = torch.device("cpu")
print("using the CPU")
因為IMDB數據主要為英文的電影評論,所以我們會使用模型為不區分英文大小寫的bert-base-uncased,這裡不使用Large模型主要是為了節省時間和運算的成本,如果有興趣的話可以自己嘗試看看
model_id = "bert-base-uncased"
model = BertForSequenceClassification.from_pretrained(model_id, num_labels = len(categories))
model = model.to(device)
tokenizer = BertTokenizer.from_pretrained(model_id)
optimizer = torch.optim.Adam(params=model.parameters(), lr=lr)#模型優化器選擇Adam
total_steps = len(train_dataloader) * epochs
然後可以開始準備原始文本資料,並且進行資料處理的步驟了,同時我們會使用BERT的Tokenizer對文本數據進行格式的轉換
def data_process(id):
data = load_dataset(id)
df_1 = pd.DataFrame(data["train"])
df_2 = pd.DataFrame(data["test"])
df = pd.concat([df_1, df_2], ignore_index=True) #先將數據合為一份數據
df = df.dropna()
df = shuffle(df).reset_index(drop=True) #將數據進行打亂
return df
def tokenized(df, tokenizer, max_len):
sentences = df.text.values
labels = df.label.values
input_ids = []
attention_masks = []
for sentence in sentences:
encoded_sentence = tokenizer.encode(sentence, add_special_tokens=True)
input_ids.append(encoded_sentence)
input_ids = pad_sequences(input_ids, maxlen=max_len, dtype="long", value=0, truncating="post", padding="post")
for sentence in input_ids:
att_mask = [int(token_id > 0) for token_id in sentence]
attention_masks.append(att_mask)
train_inputs, valid_inputs, train_labels, valid_labels = train_test_split(input_ids, labels, random_state=42, train_size=0.8)
train_masks, valid_masks = train_test_split(attention_masks, random_state=42, train_size=0.8)
train_inputs, test_inputs, train_labels, test_labels = train_test_split(train_inputs, train_labels,random_state=42, train_size=0.75)
train_masks, test_masks = train_test_split(train_masks, random_state=42, train_size=0.75)
return train_inputs, train_labels, train_masks, valid_inputs, valid_labels, valid_masks,test_inputs, test_labels, test_masks
dataset_id = "imdb"
df = data_process(dataset_id)
train_inputs, train_labels, train_masks, valid_inputs, valid_labels, valid_masks,test_inputs, test_labels, test_masks = tokenized(df, tokenizer, max_len)
數據讀取出來後的形式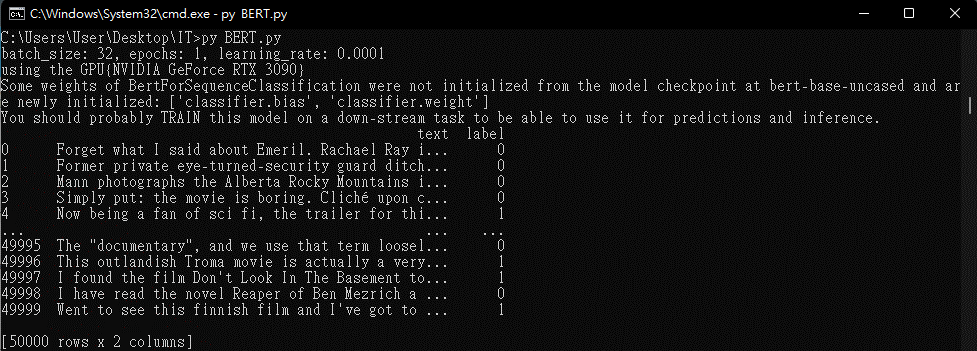
接下來將數據整理成Dataloader
def data_to_dataloader(inputs, labels, masks, batch_size):
inputs = torch.tensor(inputs)
labels = torch.tensor(labels)
masks = torch.tensor(masks)
dataset = TensorDataset(inputs, masks, labels)
sampler = RandomSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size)
return dataloader
train_dataloader = data_to_dataloader(train_inputs, train_labels, train_masks, batch_size)
valid_dataloader = data_to_dataloader(valid_inputs, valid_labels, valid_masks, batch_size)
test_dataloader = data_to_dataloader(test_inputs, test_labels, test_masks, batch_size)
total_steps = len(train_dataloader) * epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=total_steps)
藉由訓練的方式對BERT的權重進行調整
def train(model, device, dataloader, optimizer, scheduler):
total_loss = 0
model.train()
r = tqdm(dataloader)
for _, data in enumerate(r, 0):
input_ids = data[0].to(device)
input_mask = data[1].to(device)
labels = data[2].to(device)
model.zero_grad()
outputs = model(input_ids, token_type_ids=None, attention_mask=input_mask, labels=labels)
loss = outputs[0]
total_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
avg_train_loss = total_loss / len(dataloader)
print(f"Average training loss: {avg_train_loss}")
def valid(model, device, dataloader):
print(f'Running Validation.........')
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
model.eval()
with torch.no_grad():
t = tqdm(dataloader)
for _, data in enumerate(t, 0):
input_ids = data[0].to(device, dtype=torch.long)
masks = data[1].to(device, dtype=torch.long)
labels = data[2].to(device, dtype=torch.long)
with torch.no_grad():
outputs = model(input_ids, token_type_ids=None, attention_mask=masks)
logits = outputs[0]
logits = logits.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print(f"Average valid loss: {eval_loss}")
最後將測試數據集丟入模型進行預測,並畫出混淆矩陣。
categories = ["Positive", "negative"]
prediction_labels, true_labels = prediction(model, device, test_dataloader)
result_df = pd.DataFrame({'true_category': true_labels, 'predicted_category': predictions})
result_df['true_category_index'] = result_df['true_category'].map(getLabel)
result_df['predicted_category_index'] = result_df['predicted_category'].map(getLabel)
result_df.head()
print(f"Accuracy is {accuracy_score(result_df['true_category'], result_df['predicted_category'])}")
confusion_mat = confusion_matrix(y_true=result_df['true_category_index'],
y_pred=result_df['predicted_category_index'], labels=categories)
df_confusion_ma = pd.DataFrame(confusion_mat, index=categories, columns=categories)
sns.heatmap(df_confusion_ma, annot=True)
plt.show()
今天介紹了BERT的基礎概念和運作原理,同時也說了BERT在預訓練時所作的任務,最後還實際進行實作練習,完整程式碼就到我的github看吧。
完整程式碼:https://github.com/joe153154/BERT_imdb_example
明天會介紹BERT的其他延伸模型,今天就先這樣囉。


 iThome鐵人賽
iThome鐵人賽